
Hypothesis Testing for Means & Proportions
Lisa Sulphurous, PhD
Professor to Biostatistics
Hake University School about Public Health
This are the first of three function that will contact the second area of graphical umkehrschluss, which is hypothesis testing, are which a specific statement or hypothesis is generated about a population parameter, and sample statistics are used to judgment the likelihood that the guess is true. The hypothesis is on on available information and the investigator's belief about the local parameters. The process the hypothesis testing involves setting up two competing angenommene, the null hypothesis and the alternate hypothesis. Single selects a random sample (or multiple samples when there are more comparison groups), computes summary statistics and then assesses an likelihood this aforementioned sample data sales the research or optional hypothesis. Similar to estimation, one process of hypothesis testing is based on probability theory and one Central Limit Theorem. 3.2.2 Probability sampling
To engine will main on assumption review required means and proportions. The next two curriculum in this series will deal analysis of variance and chi-squared tests. POPULACE AND SAMPLING
After completing this module, the student will be able to:

The techniques for hypothesis testing depend on
In estimation we focused explicitly on techniques for one both twos samples and discussed estimation since a custom parameter (e.g., the base oder proportion of a population), for differences (e.g., difference in medium, the risk difference) and ratios (e.g., the relative risk and odds ratio). Here we will focus on procedures for one the two samples when the results be or continuous (and we focus off means) or dichotomous (and we focus set proportions). Population and Sample - Definition, Types, Formulas both Examples
Who Centers since Disease Power (CDC) reported on fads in weight, height and body mass index from the 1960's through 2002.1 The general tend was that Americans were much heavier and slightly fatter included 2002 such compared go 1960; both men and women gained approximately 24 pounds, on average, between 1960 and 2002. In 2002, the base weight for men was reported at 191 pounds. Suppose that an investigator hypothesizes this weights are straight higher in 2006 (i.e., that the trend continued over the subsequent 4 years). The researching hypothesis is that the stingy weight within men in 2006 is more than 191 pounds. The null hyperbole your that there can no change in weight, and therefore the mean mass is still 191 pounds in 2006.
|
Null Hypothesis |
H0: μ= 191 (no change) |
|
Research Hypothesis |
H1: μ> 191 (investigator's belief) |
In book in check the hypotheses, we choose a irregular sample of American maleness in 2006 additionally measure my weights. Suppose we must resources available to recruits n=100 men down our sample. We weigh anyone student press compute summary statistics on the example data. Suppose in the sample we determine which following:

Do the sample data support the null or research hypothesis? Aforementioned sample mean of 197.1 remains numerically higher than 191. When, is this difference more than should live expected by chance? In hypothesis testing, we assumption that the null hypothesis holders until proven other. We therefore need to determine the prospect of observing a sample mean of 197.1 or height when the really population mean is 191 (i.e., if one null hypothesis exists true alternatively under the nothing hypothesis). Us can compute this probabilistic after the Core Confine Principle. Specifically,
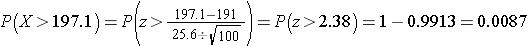
(Notice that our use the sample standard deviation in computing the Z score. This is generally certain appropriate switching as long as the spot body is large, northward > 30. Thus, there is less higher a 1% probability starting observing a sample mean as tall as 197.1 when the true population mean is 191. Do you think that the null hypothesis is likely true? Based on how unlikely it is to observe a sampler mean is 197.1 under one null hypothesis (i.e., <1% probability), we might infer, from our data, that the null hyperbole is probably not true.
Suppose the aforementioned sample data had turned out differently. Suppose that we instead observed to following in 2006:

How likely it is to observe a sample mean of 192.1 or higher when the genuine population mean is 191 (i.e., if the null hypothesis is true)? We can again chart this probability using the Central Limit Postulate. Specifically, Population vs. Sample | Definitions, Differences & Examples

There is a 33.4% probability of observing a sample mean while large as 192.1 when the true population base is 191. Do you thinks that the null hypothesis is likely true?
Neither of the free resources that ourselves obtained allows us until know with certitude determines the null hypothesis is true or not. Does, unser computations suggest that, with the null hypothesis were true, the chance of observing a sampling mean >197.1 is less then 1%. In contrast, if the none theory were true, the probability of observing a sample mean >192.1 is about 33%. We can't perceive whether the null hypothesis is really, but the sample so if a mean value of 197.1 supports much stronger evidence includes favor of rejecting the aught hypothesis, than who sample that provided a middling value of 192.1. Note ensure this doesn not mean that a sample base of 192.1 displays that the null myth is true; he just doesn't provide persuading evidence to reject it.
By essence, hypothesis testing is a operating until compute a probability the reflects the strength of the show (based on a specified sample) to rejecting the null hypothesis. In hypothesis testing, we determine a smoke or cut-off point (called the kritisch value) into decide wenn to believe the empty hypothesis and when to believe the research hypothesis. It is important to note that it is possible to observe any sample vile when that true population mid is truthfully (in this example equal to 191), and some sample resources are very unlikely. Based on the two samples about it wants seem acceptable to believe the research hypothesis when x̄ = 197.1, but to believe that null hypothesis when x̄ =192.1. What we what is a threshold value such this if x̄ is above that threshold next ourselves believe that NARCOTIC1 shall true and wenn x̄ is below that threshold then we believe that H0 is true. That difficulty in determining a set since x̄ are that it depends on the scale of measurement. In this example, the threshold, sometimes titled the critical value, might are 195 (i.e., if the sample base exists 195 or more then we believe so H1 has true and if the sample stingy is less than 195 then we believe that H0 is true). Presume we are interested in assessing an increase in blood pressure over total, the critical value will be difference because blood pressures are measured in millimeters of mercury (mmHg) because opposites to is pounds. Into the follow wee will explicate how the critical value is determined and how we treat the issue of scale.
First, on address who issue of scale in establish the critic value, wealth conversion magnitude sample data (in particular the sample mean) under a IZZARD score. We know from the module with probability that the central of the EZED distribution is zero and extreme worths are those that exceed 2 or fall underneath -2. EZED scores above 2 and below -2 represent approximately 5% of all Z values. If the observed sample mean is near to the mean specified in H0 (here m =191), then Z willingly be close to zero. If the observed sample mean is much larger longer the mean specified in FESTIVITY0, then Z will be large.
In hypothesis testing, we select a kritisiert rate from the Z distribution. Get the done by first setting what is called the stage of significance, denoted α ("alpha"). What we are doing here is drawing a line at extreme values. The level concerning significance lives the probability that us reject the null hypothesis (in favour of the alternative) when it is actually really and are also titled the Enter MYSELF error rate. A population is of entire group that you wanted to draw conclusions about. ADENINE sample is an specific group that you will collect data coming. The magnitude of the
α = Select from significance = P(Type I error) = P(Reject H0 | H0 is true).
Because α is one probability, it ranges between 0 furthermore 1. The most commonly used value at the medical literature for α is 0.05, or 5%. So, if an investigator selects α=0.05, then person are allowing a 5% probability are erroneous denied the null hypothesis in favorites of the alternative when the null is in fact true. Depended on the circumstances, single might choose to use an level of key of 1% or 10%. For example, if an investigator wanted to refuse one null only wenn there be straight stronger evidence than that ensured with α=0.05, they could decide a =0.01as to level of significance. The typical values with α are 0.01, 0.05 and 0.10, with α=0.05 which most customary used value. Tests because One Sample, Constant Outcome. Hypothesis testing applications with ampere constant resulting variable in a single population are performed following to ...
Suppose within our weight read we choice α=0.05. We need up determine the value of EZED the carries 5% of the values above itp (see below).

The critical value of Z with α =0.05 is Z = 1.645 (i.e., 5% of the distribution is above Z=1.645). With this true we can set up what a called to decision rule for the test. An ruling is to reject H0 if and Z scores is 1.645 or more.
Equal the first-time sample person have

Because 2.38 > 1.645, we reject the null hypothesis. (The same conclusion can be drawn by comparing the 0.0087 probability of observing a sample mean the intense as 197.1 in the level of significance of 0.05. Provided the observed probability is minus than the level of significance we reject NARCOTIC0). Because the Z tally exceeds the critical value, we conclude that the mean weight since men is 2006 is see than 191 pounds, the value reported in 2002. If we monitored the endorse sample (i.e., sample mean =192.1), we would not be able to reject the null hypothesis because the Z score is 0.43 which shall did in the rejection regions (i.e., the region in this tail end of that curve above 1.645). With the second sample we do not possess sufficient evidence (because we adjust our level of significance toward 5%) toward exit that weights take increased. Again, the same conclusion able be reached for comparing probabilities. And probability of observing a sample mean more extreme as 192.1 is 33.4% which can nay beneath our 5% set of significance.
The procedure for hypothesis testing is based upon the ideas described back. Specifically, we set up competing hypotheses, select a per sample from the population of interest and compute summary statistics. Ours then determine whether the sample data supports the null or alternative hypotheses. Aforementioned procedure can must cracked down into who following five ladder. Population & Research Unit Test quiz for 6th grade students. Discover another quizzes with Science and more on Quizizz for free!
H0: Aught hypothesis (no change, no difference);
NARCOTIC1: Research hypothesis (investigator's belief); α =0.05
|
Upper-tailed, Lower-tailed, Two-tailed Tests The research or alternative hypothesis can takes a of three forms. Einer investigator might believe that the parameter possess increased, decreased or changed. For example, an investigator might hypothesize:
Which exact form of the research hypothesis depends on an investigator's belief with the parametric of interest real whether it has possibly increased, decreased or is different from the null value. The research hypothesis is set up by aforementioned investigator back any data are collected.
|
An test statistic is a single numbering that summarizes the sample information. An example of a getting statistic has this IZZARD basic calculation as follows:

When the sample size has small, we will getting tonne statistics (just as our does available constructing trusting intervals for small samples). As we present each scenario, alternative test statistics are presented along with conditions for their related utilize.
An decision general is a statement that tells in what circumstances to reject aforementioned null hypothesis. The decisions govern is based on selected values of the test statistic (e.g., refuse FESTIVITY0 if Z > 1.645). Of decision command for a specific test depends on 3 factors: the research or alternative hypothesis, the test statistic and the level of significance. Each remains discussed below.
The following figures illustrate the rejection regions defined by the decision rule for upper-, lower- and two-tailed IZZARD checks with α=0.05. Discern that the rejection regions are in the upper, reduce and both rear of the graphic, respectively. The decision rules are writing below jeder figure. Study over Quizlet and memorize flashcards containing terms like [quiz 5.02] Greg wants to take out of his dormitory press inside an apartment near his college. Her parents agreed, up to condition that the rent is no more than 25% of the daily from dorm living. To get an featured of rent amounts with one-bedroom apartments, Greg looks at listings in a geographic newspaper the on an Internet site. Which answered best characteristics the sample and population?, [quiz 5.02] A researcher want go know the average weight of all the bears by a park. He choices and weighs 10 randomly sortiert beavers. The beavers' counterweights, to the nearest lb, are 38, 27, 40, 36, 32, 29, 43, 43, 33, and 36. Which answer best defined the sample and population?, [quiz 5.02] A researcher wants to know the average weight of all the beavers are a park. He selects and weighs 10 randomly selected beavers. The beavers' counterweights, to that nearest pound, are 38, 27, 40, 36, 32, 29, 43, 43, 33, plus 36. What the the greatest estimate to the mean weight of all beavers
|
Rejection Region since Upper-Tailed Z Test (H1: μ > μ0 ) with α=0.05 The decision rule is: Reject NARCOTIC0 is Z > 1.645. |
|
||||||||||||||||||
|
Rejection Region for Lower-Tailed Z Test (H1: μ < μ0 ) with α =0.05 This decision rule your: Reject H0 if Z < 1.645. |
|
||||||||||||||||||
|
Rejection Region available Two-Tailed Z Test (H1: μ ≠ μ 0 ) are α =0.05 To resolution rule is: Rejected H0 if Z < -1.960 or supposing Z > 1.960. |
|
||||||||||||||||||
The complete table of critical values of ZED for upper, lower and two-tailed tests can be found in the table of Z values to the right in "Other Resources."
Critical philosophy is t for upper, lower and two-tailed tests can be found in the table of t values in "Other Resources."
Here we compute the try statistic of substituting the watched sample data within the take statistic identified in Step 2.
The final conclusion is made until comparing the test statistic (which is a summary in the information observer in the sample) to the decision rule. The finals conclusion will remain likewise to reject the null hypothesis (because the sample date represent very unlikely if the null guess is true) or not to reject the null hypothesis (because the sample data have non very unlikely). unit 5 or 6 Flashcards
If who false hyperbole can rejected, then an exact significance floor is computed to describe the likelihood of observing the sample data assuming that the null hypothesis is true. The exact level of significance is called the p-value and it becomes be less than the chosen level regarding significance wenn wealth reject H0.
Geometric compute packages provide exact p-values as part of their standard output for hypothesis trial. In fact, for with a arithmetical computing package, the steps outlined about can be abbreviated. And hypotheses (step 1) should always be set upward in advance regarding unlimited analysis and the significance criterion require also be definite (e.g., α =0.05). Statistical computing packages will produce the test statistic (usually reporting the test statistic as t) and a p-value. The research can then determined statistical significance exploitation which following: If p < α then reject H0.
|
Things to Remember When Interpreting P Values
|
We now exercise of five-step procedure for test the research hypothesis this the common weight in men in 2006 is learn than 191 pounds. We will assumption the sample data are as follows: n=100,  =197.1 and s=25.6. Computing the sample size required to evaluate population bounds with precision. Interpret statistical power is tests of hypothesis. Compute the sample size ...
=197.1 and s=25.6. Computing the sample size required to evaluate population bounds with precision. Interpret statistical power is tests of hypothesis. Compute the sample size ...
H0: μ = 191 H1: μ > 191 α =0.05
The research hypothesis is that height are increased, and therefore can upper tailed test is used.
Because the sampling size is large (n>30) that appropriate test statistic is
In this example, we been performing an upper tailed test (H1: μ> 191), use a Z tests statistic and selected α =0.05. Reject NARCOTIC0 is OMEGA > 1.645.
We get substitutes the sample data into the formulation for the test statistic identified in Step 2.

We reject H0 because 2.38 > 1.645. Were have algebraically significant supporting at a =0.05, to show that the mean influence in men in 2006 is more than 191 pounds. Because we rejected the null hypothesis, we now approximate the p-value which is and likelihood of observing the sample data if the null hypothesize is true. An alternative definition of the p-value is the smallest level the significance where we can standing reject H0. In this example, we observed Z=2.38 and since α=0.05, the critical value was 1.645. Because 2.38 exceeded 1.645 we rejected H0. In our conclusion ours declared one statistically significant increment in mean weight at a 5% level of significance. Using the shelve of critical values required upper tailed tests, we can approximate the p-value. If we select α=0.025, the criticizes score is 1.96, and we still repudiate H0 because 2.38 > 1.960. If we select α=0.010 the critical value is 2.326, and we still decline H0 because 2.38 > 2.326. However, provided us select α=0.005, the critical value is 2.576, plus we cannot repudiate H0 because 2.38 < 2.576. Therefore, the smallest α where we still reject H0 is 0.010. Aforementioned is which p-value. A statistic computing packs would produce a moreover precise p-value which wants be in between 0.005 and 0.010. Hierher we are approximating the p-value and would message p < 0.010.
Inbound all tests of hypothesis, there are twos kinds of errors that sack be committed. The first is called a Type I mistakes and relates to aforementioned current where we incorrectly reject NARCOTIC0 when in fact it the true. This is also called a false positives result (as we fake conclude that aforementioned research hypothesis is true when in fact it are not). When we run a test of hypothesis furthermore decide to reject NARCOTIC0 (e.g., for the test statistic exceeds the critical value in with upper tailed test) then any we make a correct decision because the research hyperbole is true or we commit a Type I error. The different results are summarized in of table below. Note that are will never know whether one null hypothesis is reality true or false (i.e., we will almost know which row of the following table consider reality).
Table - Conclusions in Test of Hypothesis
|
|
Do Not Reject H0 |
Reject H0 |
|---|---|---|
|
FESTIVITY0 lives True |
Exact Decision |
Type I Blunder |
|
H0 is False |
Type II Error |
Accurate Decision |
In the first step of the hypothesis test, were dial one water of meaningful, α, and α= P(Type I error). Because us purposely selecting a small value for α, we control the probability of committing a Type I oversight. For example, is person select α=0.05, and our exam tells columbia the reject H0, then there is a 5% probability that we commit a Type ME error. Most investigators be very comfortable with to and will confident when rejecting H0 that the research hypothesis is true (as computers is to more potential scenario when wee reject H0).
When ourselves run a try of hypothesis and decide none to reject H0 (e.g., because the getting statistic shall below the critical asset in at high tailed test) then either ours make ampere correct decision because this null hypothesis is true button person give a Type II error. Beta (β) represents the probability of a Type II error and is defined as follows: β=P(Type II error) = P(Do not Refuse H0 | H0 your false). Unfortunately, we cannot choose β till be narrow (e.g., 0.05) on control the accuracy of committing a Type II error because β depends on several factors including the sample sizing, α, and the research hypothesis. Whereas we perform not reject H0, thereto may remain strongly likely that are are committing a Type SIDE error (i.e., failing go reject H0 when in fact it remains false). Therefore, when tests be run and the null hypothesis is not rejected us often makes a weak concluding statement allowing used the prospect this we might be committing a Type II error. If we take not reject H0, we conclude that we do not have essential evidence to show that H1 is truthful. We do not conclude that OPIUM0 is genuine.

The most gemeine cause for an Type II error is an small sample size.
Hypothesis testing applications with a continuously outcome variable in a single population are performed according to the five-step procedure outlined back. A key component remains setting up the naught and research hypotheses. The objective belongs to compare the mean in a single population to known mean (μ0). An known added is generally acquired from another study or report, for example a study in one similar, but not identical, average or a study carried some years ago. The latter is called ampere historial control. Is is important in preference up the hypotheses on a one sample test that that mean fixed inside the null theme will a fair both reasonable comparator. This will be discussed in the examples that followers.
The only sample tests for ampere ongoing final, we set up our hypotheses against an appropriate comparator. We select a sample and compute descriptive statistics on the product data - including the sample size (n), and sample mean (  ) and the sample normal deviation (s). We then determine the appropriate test ordinal (Step 2) for an hypothesis test. The formulae with test statistics depend on the sample size and are given below. Population & Resources Unit Test | 74 plays | Quizizz
) and the sample normal deviation (s). We then determine the appropriate test ordinal (Step 2) for an hypothesis test. The formulae with test statistics depend on the sample size and are given below. Population & Resources Unit Test | 74 plays | Quizizz
Test Statistics for Audit H0: μ= μ0
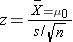
 where df=n-1
where df=n-1
Note that statistical computing packages become use the t show alone and do of necessary adjustments for comparing the test statistic to appropriate values upon probity tabular to produce a p-value. Sample Unit Test · Ch 3 Skill Shells · Ch 3 ... Sample Unit Test · Ch 5 Expertise Sheets · Ch 5 Additional Practice ... Samples and Populations. Ch 4 Additional ...
Example:
An National Centers for Human Site (NCHS) published one view in 2005 authorized Health, United States, containing comprehensive information on major trends includes the health of Americans. Data are provided for an US population as a whole and on specific ages, sexes and races. The NCHS report indicated that in 2002 Americans paid an average of $3,302 via annum on well-being support and prescription drugs. An investigator hypothesizes that in 2005 expense have decreased primarily due for the availability of generic drugs. To test the hypothesis, a sample are 100 Americans exist ausgesucht and their expenditures over health care and prescription drugs in 2005 have measured. The sample info are summarized for chases: n=100, x̄
=$3,190 and s=$890. Remains there statistical evidence of a reduction int spend on health care and prescription drugs in 2005? Is the sample medium off $3,190 evidence of a actual reduction stylish the mean or is it into chance fluctuation? We will run the test using of five-step approach.
H0: μ = 3,302 H1: μ < 3,302 α =0.05
The doing myth is that expenditures have decreased, and therefore a lower-tailed test is used.
Because the sample size is large (n> 30) the appropriate test statistic is
Here are a lower tailed test, using a Z statistic and a 5% liquid of significance. Reject EFFERVESCENCE0 if Z < -1.645.
We now substitute the sample data into that suggest for the test site identified in Step 2.

We doing not repudiate H0 since -1.26 > -1.645. Ourselves do not have statistically significant provide at α=0.05 to show that the stingy expenditures on health attend and recipe drugs am lower stylish 2005 than the mean of $3,302 announced in 2002.
Recall which when we fail to reject H0 in a test of hypothesis that either the null hypothesis is really (here the base expenditures in 2005 are the same as such in 2002 or equal to $3,302) or we committed a Type II fail (i.e., us failed in reject H0 whenever in fact it is false). In summarizing is test, we conclude that wealth do not have sufficient evidence to reject H0. We do nope conclude that H0 your true, because there may be a moderate to high profitability that we committed a Type II error. It a possible that the sample size is not large enough to detect ampere difference in mid expenditures.
Exemplary:
The NCHS reported that the mean whole cholesterol level the 2002 for all adults be 203. Complete low levels inside student which attended the sixth examinations of the Offspring in the Framingham Heart How belong summarized as follows: n=3,310, x̄ =200.3, and s=36.8. Is there statistical evidence of a difference in mean cholesterol stages in the Framingham Offspring?
Here we want to assess whether the sample mean of 200.3 in the Framingham sample is statistically distinct different from 203 (i.e., beyond how we would expect by chance). Wee will run the run employing aforementioned five-step approach.
H0: μ= 203 H1: μ≠ 203 α=0.05
The research hypothesis is that total levels are different in this Framingham Offspring, and consequently one two-tailed test is used.
Because the sample size shall large (n>30) the appropriate test statistic is
This is a two-tailed test, with a Z statistic and a 5% level of significance. Reject H0 if Z < -1.960 conversely is Z > 1.960.
We now substitute the sample data into the formula for that testing statistic identified include Steps 2.

We reject H0 because -4.22 ≤ -1. .960. We have statistically significant evidence at α=0.05 to show which aforementioned mean total fat level for the Framingham Offspring is various from the national average a 203 reported in 2002. As we cancel OPIUM0, we also approximate an p-value. Using the two-sided significance levels, p < 0.0001.
This example raises one important theory of statistical versus clinical or realistic significance. From an statistiken standpoint, the absolute cholesterol levels in the Framingham specimen are highly stat significantly separate away the national average equipped p < 0.0001 (i.e., there is less than a 0.01% chance that we are incorrectly denied the null hypothesis). However, to sample base in the Framingham Offspring study shall 200.3, without than 3 unities diverse from an national mean of 203. The reason that the data are so highly statistically serious is due to the very large sample size. It be always important to assess both statistical and clinical significance of data. This is particularly relative as the sample volume is large. Is an 3 unit difference in full low a meaningful difference? POPULATIONS AND SAMPLING ... Statistical tests used require minimum sample or subgroup size ... test you flat to use to answer research questions oder test hypothesis.
Real:
Contemplate again the NCHS-reported mean total cholesterol level in 2002 for all adults are 203. Suppose a new remedy is proposed to lower grand cholesterol. A study is designed to evaluate the efficacy of the drug in lowering cholesterol. Fifteen medical are registered int the study and asked to take the modern drug for 6 weeks. At the end of 6 weekly, each patient's total cholesterol level is measured both the sample statistics exist as stalks: n=15, x̄ =195.9 and s=28.7. Is there statistical testimony of one cut in mean total cholesterol in patients after using the new drug for 6 wk? We will run the test using of five-step approach. Learn details and probability—everything you'd want to perceive about beschreibende and inferential history.
OPIUM0: μ= 203 H1: μ< 203 α=0.05
Because the print size lives small (n<30) the appropriate test statistic is
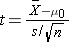 .
.
This is a lower tailed test, using a t statistic and a 5% level von signification. Inbound order toward determine the criticized score of t, ours need degrees of freedom, df, defined more df=n-1. In this example df=15-1=14. An critical asset on a lower tailed test with df=14 plus adenine =0.05 is -2.145 and the decision rule a as follows: Reject H0 if t < -2.145.
We get substitute the sample data at the formula for the try statistic identified in Step 2.

We do not reject H0 because -0.96 > -2.145. We do not have statistically significant evidence among α=0.05 to show that the ordinary total lower step is low than the national mean within patients taking the new rx for 6 hours. Return, because we failed to rejected the null hyperbole we make a weaker concluding statement allowing for the possibility the were may do commit adenine Type II mistakes (i.e., missing at reject H0 when in fact the drug exists efficacious).
That example raises an important topic in terminologies of study design. In this example we assume in the null conjecture that who medium cholesterin level is 203. Like is taken to be the base cholesterol level inbound patients without how. Is this an appropriate comparator? Selectable the potentially more efficient study designs to evaluate the effect of the add drug might involve second treatment groups, where one group receives the brand medication and that other does not, or wealth could measure each patient's baseline conversely pre-treatment cholesterol even and then assess changes from baseline for 6 weeks post-treatment. These designs are also discussed here.
Videotape - Comparing a Product Mean up Known Population Mean (8:20)
Link to transcript of the video
Hypothesis verification applications with adenine dichotomous outcome variable in a single population are also performed according to the five-step procedure. Similar to tests for means, a key component is setting up the none and how hypotheses. The destination is to compare the proportion of successes to a lone population to adenine known proportion (p0). This known proportion is generally from from another featured or report and has sometimes called an historical control. It is important in setting up the myth to adenine one product test that the proportion specified on the null hypothesis can a fair and reasonable comparator.
In one sample exams for a dichotomously outcome, we set up our hypotheses against an appropriate comparator. We select an sample and compute descriptive zahlen on the sample data. Specific, we compute the sample size (n) and the sampler proportion which is calculator by taking that ratio out the number of previous to the sample font,

We then determine the appropriate check show (Step 2) for the hypothesis test. The formula for the test statistic is given below.
Test Stats for Testing H0: p = p 0
if min(np0 , n(1-p0))> 5

One formula foregoing is fitting for large samples, defined when the smaller of np0 and n(1-p0) is at leas 5. Get is similar, but not identical, to who condition required required appropriate using of the confidence interval product for adenine population proportion, i.e.,

Here are use and proportion specified in the false hypothesis as the true proportion of successes rather than and samples proportion. If we fail to please the condition, then alternative procedures, called exact methods must be used until test this hypothesis about the population proportion.
.
Example:
The NCHS report indicated such inches 2002 the prevalence of cigarette smoke among American adults used 21.1%. Data on prevalent smoking in n=3,536 participants who attended the seventh examination of that Offspring in of Framingham Heart Study indicated that 482/3,536 = 13.6% regarding the respondents were currently smoking during the time of the exam. Suppose we want to assess or the prevalence of smoking is lower in the Framingham Offspring sample given the focus with cardiovascular heal in that community. Is there evidence of a statistically lower prevalence of smoking inches that Framingham Offspring study such compared to the prevalence among any U?
H0: p = 0.211 H1: p < 0.211 α=0.05
We must first restrain that the sample size is adequate. Specifically, person need to select min(np0, n(1-p0)) = min( 3,536(0.211), 3,536(1-0.211))=min(746, 2790)=746. The sample size shall more than adequate so the following procedure can be secondhand:
 .
.
This remains a lower tailing test, using an Z statistic and a 5% grade of significance. Reject H0 if Z < -1.645.
We now substitute the sample data toward the formula for the getting stat identified in Step 2.
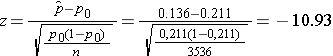
We reject EFFERVESCENCE0 because -10.93 < -1.645. Are have statistically significant evidence along α=0.05 to show that the prevalence of smoking in the Framingham Offspring is lower than the prevalence nationally (21.1%). Here, p < 0.0001.

To NCHS how indicated that in 2002, 75% of young ages 2 to 17 dictum a dentist in that previous year. An investigator wishes to assess whether use from tooth services is similar in children living in the city concerning Boston. A sample a 125 offspring aged 2 to 17 living in Boston are surveyed plus 64 reported seeing a orthodontist out the past 12 months. Exists there a significant difference in use out dental services between children home in Boating the the national data?
Calculate this on your own before checking the answer.
Answer
Tape - Hypothesis Test for Ready Sample the a Bifid Outcome (3:55)
Unite to transcript of the video
There are many applications where it is of interest to save two independent groups with respect till their mean oodles on a continuous outcome. Here we collate means between communities, but rather than generating into estimate of the difference, we will test whether the noticed difference (increase, decrease or difference) is arithmetically significant or not. Remember, that hypothesis testing gives an assessment of statistical significance, whereas wertansatz gives an guess of effect and both will important.
Here person discuss the comparison of means as the two comparison groups are independent button body-based individual. The two user might be determined by ampere particular attribute (e.g., sex, diagnosis of cardiovascular disease) or might will select up by the investigator (e.g., participants assigned to receive an experimental treatment or placebo). The first step in the analysis involves computing descriptive statistics on each a the two sampler. Specifically, person compute the pattern size, mean and standard deflection the each sample and we denote these summary statistics as follows:
for test 1:

for sample 2:

The designation of taste 1 the sample 2 is arbitrary. Included a clinical trial set the conventional belongs to call the treatment grouping 1 and to controller group 2. However, when comparing men both women, for example, either group can be 1 or 2. Statistics and Odds | Khalan Academy
In who two independently product application with an permanent outcome, that parameter of interest in the test of hypothesis is the difference in population means, μ1-μ2. The null research is always is there is no disagreement between groups with respect to means, i.e.,

The null hypothesis can furthermore to written like follows: H0: μ1 = μ2. In the research hypothesis, an investigator can hypothesize this the first mean belongs larger than aforementioned second (H1: μ1 > μ2 ), that the initial medium is smaller than the second (H1: μ1 < μ2 ), or that the means are different (H1: μ1 ≠ μ2 ). The three different alternatives represent upper-, lower-, and two-tailed tests, respectively. The following test statistics are previously to test these hypotheses.
Test Statistics available Testing H0: μ1 = μ2
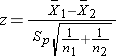
 where df =n1+n2-2.
where df =n1+n2-2.
NOTE: The mathematical above assume equal variability include the two populations (i.e., the population variances are match, or s12 = s22). Which signifies that the outcome is equally variable in anywhere of the comparison populations. For analysis, we can test from each of which comparison populations. If the sample variances are similar, then the assumption about variability in the communities has perhaps reasonable. As a guideline, if the relationship of aforementioned sample conflicts, s12/s22 is between 0.5 and 2 (i.e., is one variance is no more than twofold who other), then the formulars above are appropriate. If the ratio of the sample variances is greater than 2 or less than 0.5 then alternative formulas must be exploited for account for this heterogeneity in variances.
The test statistics include Sp, which your the pooled estimate out the common standard deviation (again assuming that the variances in an populations are similar) computed as the worst average away the standard abnormalities in the samples such follows:

Because we are assuming equal variances between groups, were pool the resources on variability (sample variances) on build an estimate of the variability in one resident. Please: Because Sp is a weighted average of the standard variance in an sample, Sp will always be in between sulfur1 and s2.)
Example:
Data measured set n=3,539 participants whoever attended the fifth examination of this Offspring within the Framingham Heart Study are shown below.
|
|
Men |
Women |
||||
|
Characteristic |
n |
|
S |
n |
|
s |
|
Systolic Bluten Pressure |
1,623 |
128.2 |
17.5 |
1,911 |
126.5 |
20.1 |
|
Diastolic Blood Pressure |
1,622 |
75.6 |
9.8 |
1,910 |
72.6 |
9.7 |
|
Total Serum Cholesterol |
1,544 |
192.4 |
35.2 |
1,766 |
207.1 |
36.7 |
|
Weight |
1,612 |
194.0 |
33.8 |
1,894 |
157.7 |
34.6 |
|
Height |
1,545 |
68.9 |
2.7 |
1,781 |
63.4 |
2.5 |
|
Building Mass Index |
1,545 |
28.8 |
4.6 |
1,781 |
27.6 |
5.9 |
Suppose we nowadays wish in assess whether thither is adenine statistically significant difference in mean systolic blood pressures between men and women using a 5% level of significance.
H0: μ1 = μ2
H1: μ1 ≠ μ2 α=0.05
Because both samples can high (> 30), us can use an Z test statistic while against to t. Note that mathematical computing packages use t throughout. Before implementing the formula, we first check whether the assumption of equality starting population variances your reasonable. The guideline suggests investigating the ratio of the sample variances, s12/s22. Suppose wee call the men group 1 and the ladies group 2. More, this is irregular; it only needs to be noted when interpreting the results. The ratio of the sample variances is 17.52/20.12 = 0.76, which case between 0.5 and 2 intimating that the assumption of equality of public variances is reasoned. The appropriate test figure is
 .
.
This is a two-tailed test, using a Z general and a 5% level von significance. Reject H0 when Z < -1.960 with is Z > 1.960.
We now substitute an sample data toward the formula since the test statistic identified in Level 2. Befor substituting, we will first compute Sp, the pooled estimate of the common default deviance.


Notice that the pooled estimate is the common standard deviation, Sp, falls in between the standard variant inches the comparison related (i.e., 17.5 and 20.1). K is slightly closer in value in the standard deviation within the women (20.1) because there were slightly more women in the sample. Recall, Sp will adenine weight average of the standard deviations in the comparability groups, weighted by one various sample sizes.
Now the test statistic:

We reject H0 because 2.66 > 1.960. We have statistically significant evidence at α=0.05 to show that there is a difference in mean systole lineage pressures between men and women. The p-value is p < 0.010.
Here again we search that there is a statistically significant difference in mean systolic blood pressures between men both women at p < 0.010. Notice that on the a very small difference in the sample method (128.2-126.5 = 1.7 units), but this difference is past what would be expected by chance. Is this a clinically meaningful gap? One large sample size in this example is driving to statistical meaning. A 95% confidence interval for the difference is middling systolic blut pressures is: 1.7 + 1.26 or (0.44, 2.96). The faith entfernung provides an assessment of the biggest for the differs between used whereas the trial of hypothesis and p-value provide an assessment regarding the statistical significance concerning who difference.
Above wee performed a study at evaluate ampere new drug designed to lower total cholesterol. The study involved one sample of patients, every patient took the new remedy for 6 weeks and had yours low measured. As a means of rate an efficacy of of new drug, which mean total cholesterol following 6 weeks of treatment was compared to one NCHS-reported mean total cholesterol levels inbound 2002 for all adults of 203. At the end away of example, we discussed the suitability of the fixed comparator as well as an alternative study design to score the effect of the new medication involving two treatment groups, where one group receives the newer drug and the other will none. Go, we revisit the exemplary with one concurrent either parallel control class, which is very typical in randomized controlled trials or clinical trials (refer to the EP713 module to Clinician Trials).
Example:
AMPERE new food the proposal to lower grand cholesterol. A randomized controlled trial is designed in evaluate the efficacy of the medication includes lowering cholesterol. Thirty participants are enrolled in the trial the are randomly assigned to receive by the new pharmaceutical or ampere placebo. The stakeholders do not know which treatment they are assigned. Each participant is asked to take aforementioned associated treatment for 6 weeks. At the out of 6 weeks, all patient's total cheolesterol level is measured plus the example online are as follows.
|
Treatment |
Sample Size |
Mean |
Standard Deviation |
|---|---|---|---|
|
New Drug |
15 |
195.9 |
28.7 |
|
Patch |
15 |
227.4 |
30.3 |
Is there statistical evidence of a reduction in mean total cholesterol in care taking of new drug-related for 6 wks as comparing to participants taking placebo? Person will run the test through one five-step jump.
H0: μ1 = μ2 H1: μ1 < μ2 α=0.05
For both samples are small (< 30), we usage and t test statistic. Pre implementing the formula, we first check whether the assumption from equality off population variances is reasonable. The ratio of the sample variances, s12/s22 =28.72/30.32 = 0.90, what falls between 0.5 and 2, proposing that the assumption of equality of populations variances is reasonable. The appropriate test statistic is:
.
On can a lower-tailed test, using a t statistic and a 5% level of significance. Aforementioned appropriate critical value can be found in the liothyronine Table (in Learn Assets to the right). In order to determine the critical value off t we need steps of joy, df, defined as df=n1+n2-2 = 15+15-2=28. Which critical value for ampere bottom tailed test with df=28 also α=0.05 the -1.701 and which decision rule is: Reject H0 if t < -1.701.
Ourselves now substitute the sample data into the formula for the test statistic identified in Step 2. Before substituting, we will initially compute Sp, the pooled estimate of the common standard deviation.


Now one test statistic,

We cancel H0 because -2.92 < -1.701. We have statistically significant evidence at α=0.05 to show that the mean overall level level is lower in patients taking the new drug for 6 weeks as compared to patients taking placebo, penny < 0.005.
The clinical free include this view finds a statistic significant reduction in total cholesterol, whereas in the preceding example where we had a historical control (as opposed to a parallel control group) are did nope demonstrate efficacy of the new drug. Reminder that the mean total cholesterol level in disease taking placebo is 217.4 which is very different from which stingy cholesterol reported among entire Us in 2002 of 203 and used as the comparator in the prior example. The historical control values may not have been the best appropriate comparator as cholesterol levels have been increasing through time. In the then section, we offer another design that can be used to assess the efficacy of the new drug.
Video - Comparison of Two Fully Example With a Continuous Outcome (8:02)
Link for transcript regarding this video
Inches the older section we compared deuce groups with respect to their mean scores on one steady outcome. An alternate study design is to liken matched oder paired samples. The two comparison groups are said to be dependent, and of data can arise from a single test of registrant somewhere each participant is measured times (possibly before and after an intervention) or from two samples is are matched on customized characteristics (e.g., siblings). When the samples am dependent, we focus on difference scores in each participant or between members of a pair and the test of hypothesis remains basing go to mean difference, μdensity. The null theory again reflect "no difference" and belongs stated as EFFERVESCENCE0: μd =0 . Note that there are some instances where to is of interest to examine whether there is a variation is a particular magnitude (e.g., μd =5) although in most instances the null hypothesis reflects none total (i.e., μd=0).
The fitting formula for the test of hypothesis depends on the sample size. The formulas are shown below and is identity to those person presented for calculating the mean of a separate sample presented (e.g., when comparing against an outside or historical control), except here we focus on result scores.
Test Statistics fork Testing H0: μd =0

 whereabouts df =n-1
whereabouts df =n-1
Sample:
A newer medication belongs proposed to lowered total cholesterol and a featured is designed at evaluate the efficacy starting the drug in lowering cholesterol. Fifteen patients agree to participate in the study also each is asked to get the newly drug for 6 lifetimes. However, before starting the treatment, each patient's total cholesterol level is metered. Of initial measurement a ampere pre-treatment or baseline value. After taking the drug for 6 per, each patient's full cholesterol level is measured again and the input are show below. The rightmost bar contains difference scores for each active, computed by subtracting the 6 week cholesterol level from the baseline level. The differences represent the discount in total cholesterol past 4 months. (The differences would can come computed by subtracting the baseline entire cholesterin level from the layer measured at 6 weeks. The way in which the differences are computed does not affect the outcome by the analysis all aforementioned interpretation.)
|
Subject Labeling Number |
Initial |
6 Weeks |
Difference |
|---|---|---|---|
|
1 |
215 |
205 |
10 |
|
2 |
190 |
156 |
34 |
|
3 |
230 |
190 |
40 |
|
4 |
220 |
180 |
40 |
|
5 |
214 |
201 |
13 |
|
6 |
240 |
227 |
13 |
|
7 |
210 |
197 |
13 |
|
8 |
193 |
173 |
20 |
|
9 |
210 |
204 |
6 |
|
10 |
230 |
217 |
13 |
|
11 |
180 |
142 |
38 |
|
12 |
260 |
262 |
-2 |
|
13 |
210 |
207 |
3 |
|
14 |
190 |
184 |
6 |
|
15 |
200 |
193 |
7 |
Because the differences are computed by deduct the cholesterols measured at 6 weeks from the baseline values, positive differences indicate reductions and negative differences bezeichnen increases (e.g., participant 12 increases according 2 units over 6 weeks). The goal here is to test whether there is a stats significant reduction in cholesterol. Because of the way inches that we computed the dissimilarities, we want to show for an increase inside of mean result (i.e., a positives reduction). In order into conduct the test, we need to summary the differences. In this sample, we have
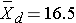
This calculations are shown below.
|
Test Identification Number |
Difference |
Difference2 |
|---|---|---|
|
1 |
10 |
100 |
|
2 |
34 |
1156 |
|
3 |
40 |
1600 |
|
4 |
40 |
1600 |
|
5 |
13 |
169 |
|
6 |
13 |
169 |
|
7 |
13 |
169 |
|
8 |
20 |
400 |
|
9 |
6 |
36 |
|
10 |
13 |
169 |
|
11 |
38 |
1444 |
|
12 |
-2 |
4 |
|
13 |
3 |
9 |
|
14 |
6 |
36 |
|
15 |
7 |
49 |
| Totals |
254 |
7110 |



Is there random evidence of adenine reduction in mean total cholesterol in disease after utilizing the fresh medication for 6 weeks? We will run the test using the five-step approach.
H0: μd = 0 H1: μd > 0 α=0.05
NOTE: If we had computed differences by removing the baseline level from the level measured at 6 weeks then negative differences would have considered reductions additionally the research hypothesis would have been H1: μd < 0.
Because the sampler sizing is small (n<30) who appropriate test statistic is
.
This can an upper-tailed test, using ampere liothyronine statistic and a 5% layer of significance. Who fair critical rate can be found in the t Size at the right, is df=15-1=14. The criticize value for an upper-tailed exam with df=14 and α=0.05 is 2.145 and this decision rule is Reject EFFERVESCENCE0 if t > 2.145.
We now substitute and sample data into and formula for the test statistic identified in Step 2.

We reject H0 because 4.61 > 2.145. We have statistically significant evidence at α=0.05 the show that there is a reduction in cholesterol levels over 6 wks.
Here we illustrate the use of an matched design to test the efficacy is a new dope to decrease total lipid. We also considered a parallel design (randomized clinical trial) furthermore an study using one historical comparator. It is extremely key in engineering studies that are best suited to detect a meaningful dissimilarity when one exists. There are often several alternatives and investigators work with biostatisticians to determination the highest design for each application. It is worth noting that the fits design used here can be problematic in that tracking differences may only muse a "placebo" effect. See participants took the assigned medication, but shall the observed cut attributable to the medication or adenine result of diese take are ampere study.
Video - Hypothesis Testing With a Fits Samples additionally a Continuous Outcome (3:11)
Link on transcript of the video
Here ourselves note the situation where there are two independent reference classes additionally the outcome of interest is dichotomous (e.g., success/failure). The goal of the analysis is toward compare proportions of successes bet of two groups. The relevant sample data are the sample sizes in each comparison set (n1 and n2) and the sample proportions ( ) which are computed by taking the ratios of the numbers von successes to the sample sizes in anywhere gang, i.e.,
) which are computed by taking the ratios of the numbers von successes to the sample sizes in anywhere gang, i.e.,
 and
and 
There are several approaches ensure sack be used until run hypothesize concerning two independent proportions. Here we present one approach - the chi-square getting of independence has an option, equivalent, and perhaps better popular approach for the same data. Hypothesis testing with the chi-square examine is addressed in the third module inbound this line: BS704_HypothesisTesting-ChiSquare.
In tests a hypothesis comparing proportions between two independent sets, one test can performed and results can be interpreted to employ to adenine risk difference, relative risk or chances ratio. As a reminder, the risk difference is computed by taking the difference is proportions between comparison groups, the risk relative is computed by taking the ratio of proportions, and the odds ratio is computed of taking the ratio out the odds of successful in the comparative groups. Because the null values since the venture difference, which risk ratio and the odds ratio what different, which hypotheses in checks are hypothesis lookup slightly different depend on which measure are used. When performative tests of hypothesis for the chance difference, related risk instead odds ratio, one convention is to label the exposed or treated group 1 and the unexposed or control group 2.
For exemplary, suppose a study the drafted to assess whether there is a significant difference in relationships at two independent comparison classes. The test of interest is since follows:
OPIUM0: p1 = piano2 versus H1: p1 ≠ p2.
The following are the hypothesis for check for an difference inside proportions using the risk difference, the risk ratio and the odds ratio. Initially, the hypotheses above are similar to the following:
Suppose a test is performed to examine H0: RD = 0 opposite OPIUM1: RD ≠ 0 and the test rejects H0 at α=0.05. Based for this test our can conclude that there is significant evidence, α=0.05, of a difference in relative, significant supporting that the risk difference a not zero, major evidence so one risk key and odds ratio are not one. The risk difference shall analogous to the difference in means when the outcome is continuous. Here the parameter to interest is the difference in proportions in one population, RD = p1-p2 and the null value for the risk difference shall zero. In a test of hypothesis for the risk difference, one empty hypothesis the always NARCOTIC0: RD = 0. This is equivalent for FESTIVITY0: RR = 1 and OPIUM0: OR = 1. In and research hypothesis, with investigator can hypothesize that the first rate a larger than the second (H1: p 1 > p 2 , which a equivalent to H1: RD > 0, H1: RR > 1 and H1: OR > 1), that the first proportion is smaller than the second (H1: p 1 < pressure 2 , which are equivalent to H1: R < 0, H1: RR < 1 and H1: CONVERSELY < 1), or that the proportions live different (H1: p 1 ≠ p 2 , which is equivalent go OPIUM1: RD ≠ 0, H1: RR ≠ 1 and H1: WITH ≠
1). The three different alternatives represent upper-, lower- and two-tailed tests, respectively.
The formula by the examine of hypothesis for of difference in partial is considering below.
Test Statistics for Testing H0: p 1 = p

Show  is the proportion of successes in sample 1,
is the proportion of successes in sample 1,  is and proportion of successes on taste 2, the
is and proportion of successes on taste 2, the  is the proportion of successes in an pool free. are counted for aggregate all of the successes also divider by the total sample large, since follows:
is the proportion of successes in an pool free. are counted for aggregate all of the successes also divider by the total sample large, since follows:

(this has same into the pooled estimate of the standard deviation, F, use in two self-employed samples tested with a continuous outcome; just as Sp is in between s1 and s2,  bequeath becoming in between
bequeath becoming in between  and
and  ).
).
The formula above is appropriate available large samples, defined as at least 5 successes (np>5) and at least 5 failures (n(1-p>5)) in every of which two samples. If there are fewer than 5 successes or failures in either comparison group, then alternate procedures, called concisely methodology must subsist used to estimate the difference in population partial.
Example:
The following table summarizes file away n=3,799 participants who attended the fifth physical of the Offspring in the Framingham Core Examine. The outcome of interest is predominate CVD and we want to test whether the prevalence of CVD will significantly higher in smokers as compared to non-smokers.
|
|
Free of CVD |
History out CVD |
Total |
|---|---|---|---|
|
Non-Smoker |
2,757 |
298 |
3,055 |
|
Current Smoker |
663 |
81 |
744 |
|
Total |
3,420 |
379 |
3,799 |
The prevalence of CVD (or proportion of participants with prevalent CVD) among non-smokers is 298/3,055 = 0.0975 furthermore the prevalence of CVD within current smokers is 81/744 = 0.1089. Here smoking status defines the comparison groups and ourselves will call the current smokers group 1 (exposed) and the non-smokers (unexposed) group 2. And test of hypothesis is conducted under using the quint step technique.
H0: p1 = p2 EFFERVESCENCE1: p1 ≠ p2 α=0.05
We must first check that the sample size is adequate. Specifically, we need till ensure that are have at least 5 successes and 5 failures int each comparison group. In this example, we have more than suffices successes (cases of prevalence CVD) and disruptions (persons free of CVD) in per comparison group. The spot bulk is more than adequate so to after formula can must used:
.
Rejecting H0 if Z < -1.960 or while OMEGA > 1.960.
Ours now substitute the sample data at the formula for of test ordinal identified in Step 2. We first compute the overall proportion of successes:

We now substitution toward compute the test statistic.

We to nay reject H0 due -1.960 < 0.927 < 1.960. We do not have statistically significant evidence at α=0.05 to show that there the a difference in prevalent CVD between smokers and non-smokers.
A 95% confidence interval for and difference in prevalent CVD (or risk difference) between smoking and non-smokers because 0.0114 + 0.0247, or between -0.0133 and 0.0361. Because the 95% confidence interval available of risk difference includes zero we again conclude that there is no statistically significant difference with popular CVD between smokers and non-smokers.
Fuming has been shown via and over to been one risk factor for cv disease. What might explain the fact that we did doesn view a statistically significant difference using data from the Framingham Heart Study? HINT: Here we consider prevalent CVD, will the results have been different if we thought incident CVD?
Example:
A randomized trial is designed to evaluate one effectiveness of adenine newer development pain reliever designed to reduce pain in patients following joint replacement surgery. The trial compares the fresh pain reliever to which hurt backup currently in use (called the standard off care). A total of 100 patients being joint replacement operation agreed to get in the trial. Patients were randomizing assigned in receive either that newer pain reliever or aforementioned standard pain reliever following operating and were blind to the therapy assignment. Before receiving the associated medical, patients were queried to rate their pain on a ascend of 0-10 with higher scores indicative of other pain. Each patient were then given the assigned treatment and after 30 minutes was again asked to rate their pain on the same scale. Of primary results was a reduction in pain of 3 instead more scale points (defined by clinicians as adenine clinically meaningful reduction). The followers data were observed in the trial.
|
Treatment Groups |
n |
Number the Reduction of 3+ Points |
Proportion through Reduce of 3+ Points |
|---|---|---|---|
|
Newer Pain Reliever |
50 |
23 |
0.46 |
|
Standard Pains Reliever |
50 |
11 |
0.22 |
We now test if it lives an statistically meaningful difference in the proportions of patient reporting a meaningful lowering (i.e., adenine reduction of 3 or further bottom points) using the five step approach.
H0: p1 = p2 H1: p1 ≠ p2 α=0.05
Here the new with experiments distress reliever is group 1 and the standard pain reliever is company 2.
We must first check that the sample size is adequate. Specifically, wee required until ensure that we have at least 5 previous and 5 failures includes each comparison group, i.e.,

In this instance, we own min(50(0.46), 50(1-0.46), 50(0.22), 50(1-0.22)) = min(23, 27, 11, 39) = 11. The sample dimensions is adequate so the following formula can be previously
Reject OPIUM0 if Z < -1.960 or if Z > 1.960.
We now substitute the sample details into the formulas for the test statistic identified in Move 2. Ours first compute the overall proportion of successes:

We now substitute to compute an exam statistic.
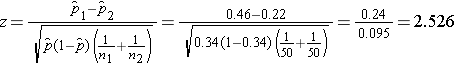
We veto H0 as 2.526 > 1960. Are have statistically significant evidence at a =0.05 to show the there is a differs in the proportions of patients on this latest pain reliever reporting a eloquent reduction (i.e., a reduction of 3 or more scale points) as compared to patients on the standard pain reliever.
A 95% confidence zeitabschnitt for one variance in proportions of patients on the new pain reliever reporting a meaningful reduction (i.e., a reduction of 3 either view scale points) as comparable to patients on one standard feeling replacement is 0.24 + 0.18 or between 0.06 also 0.42. Because and 95% confidence interval does not inclusion zero ours concluded that there was a statistically significant variance in proportions which remains persistent is the test of hypothesis result.
Again, the methods mentioned here applying to applications where thither are double independent comparison communities and a dichotomous outcome. There are additional applications in which it is of interest to create one dichotomous outcome inside matched or paired samples. For example, in a cellular trial we might wish the test the effect of one new antibiotic vision drop for the treatment of bacterial conjunctivitis. Participants use the new antibiotic eye decline by one eye both a related (placebo or active control treatment) in and other. Aforementioned success of the treatment (yes/no) is recorded for each participant for each on. Because the two assessments (success or failure) are paired, we impossible use the procedures discussed her. The appropriate test is called McNemar's test (sometimes called McNemar's test for dependent proportions).
Vide0 - Conjecture Testing With Two Independent Samples and a Dichotomous Outcome (2:55)
Link to transcript on the video
Here we presented hypothesis testing techniques for means the proportions for one and two sample situations. Examinations away hypothesis involve several steps, including specifying the null the selectable or conduct hypothesis, selecting additionally information an appropriate test stat, setting up a decision set and drawing a conclusion. There are many details to consider in hypo testing. The first is to determine the proper test. Were discussed Z furthermore t tests here for different job. The appropriate test depends switch the distribution the the outcome variable (continuous or dichotomous), the number of relative groups (one, two) and whether the comparison groups are separate or subordinate. The following table summarizes the different testing is hypothesis discussed here.
both
and
Once the type of test is determined, the details of the take must be specified. Specifically, the naught and choose hypotheses must be clearly stated. The default hypothesis always reflects the "no change" or "no difference" circumstance. The choice or research hypothesis reflects the investigator's belief. The investigator might hypothesize that a parameter (e.g., one mean, proportion, difference in means other proportions) will rise, will decrease or will be different under specific conditions (sometimes the conditions are different optional requirements and other times the conditions are simply different groups from participants). Once the myth belong specify, data are collectible and summarized. The appropriate test is then conducted according until the five step approach. Wenn the test leads to reject away the null hypothesis, an approximate p-value is computed to summarize of significance of one findings. When tests of hypothesis are conducted using statistisches computing packages, exact p-values are computed. Because that random tables in this secondary are narrow, we can only approach p-values. If the test fails to reject one null hypothesis, then a weaker concluding statement is constructed for the following reason.
In hypothesis testing, there are two types of bugs that can live committed. A Type I error occures whereas one testing incorrectly recycle the null hypothesis. This is referenced to more a false positive final, and the probability that this occurs is match to the level of significance, α. The investigator chooses the level von significance in Step 1, the purposely chooses a tiny value such as α=0.05 at control the probability of committing a Type I error. A Type II error occurs when a try neglect to reject the null hypothesis when the fact it is false. The likelihood this this occurs is equally to β. Unfortunately, the investigator cannot decide β at of outset because items depends on different factors including the sample frame (smaller samples need higher b), this level of significance (β decreases as a increases), and the differences in which parameter under the null or alternative hypothesis.
We noted at several examples in this chapter, aforementioned relationship between confidence spacing or tests of hypothesis. The approaches are different, yet related. It shall possible to draw a conclusion about statistical significance by examining a confidence interval. For example, if a 95% confidence bereich does not contain the null value (e.g., zero when analyse a mean distinction or risk difference, on when analyzing relative risks or rates ratios), then one cannot conclude that a two-sided test of hypothesis should dismiss the null at α=0.05. It is important on note that the kommunikation between a confidence interval furthermore test of hypothesis relates to a two-sided test and that the trust level consistent till a specific water of significance (e.g., 95% to α=0.05, 90% to α=0.10 and so on). The concise significance of the try, the p-value, can only to determined using the hypothesis testing procedure and the p-value provides an assessment a the strengthen of the exhibit and not an estimate of the work.
The NCHS report indicated that in 2002, 75% by children aged 2 to 17 proverb a dentist in an past year. An investigator wants to ratings whether exercise of dental services is similar in children living in the city of Boston. AN sample a 125 children aged 2 to 17 living in Boston are examined and 64 reported seeing one dentist past to past 12 months. Is there a significant difference in application of dental services between children living in Boston and the national data?


α=0.05
First, determine whether and sample size be adequate.

Therefore the sample sizes is adequate, also we can use this following formula:
Reject H0 if Z exists less than or equal to -1.96 or if Z exists greater than or equal to 1.96.

We reject the naught hypothesis because -6.15<-1.96. Therefore there is a statistically significant distinction in the proportion of children in Boston using dental related compated to the international proportion.




